Context
- What: Administration aspect of hadoop
- Need: Hadoop 2.2 with Flume, Hive, Hcatalog and MS Excel 2013
- How: Attempt to read and understand server logs generated by hadoop, for security measures
Hortonworks has this great tutorial for system admins about understanding server logs. But it did not work for me! So, I wanted to post my notes for other rookies like me.
My Experience
- Step 1: Had to get 8GB RAM on my desktop and start with the tutorial. Kept getting a WARNING for zookeeper but did not care since sandbox did not stop.
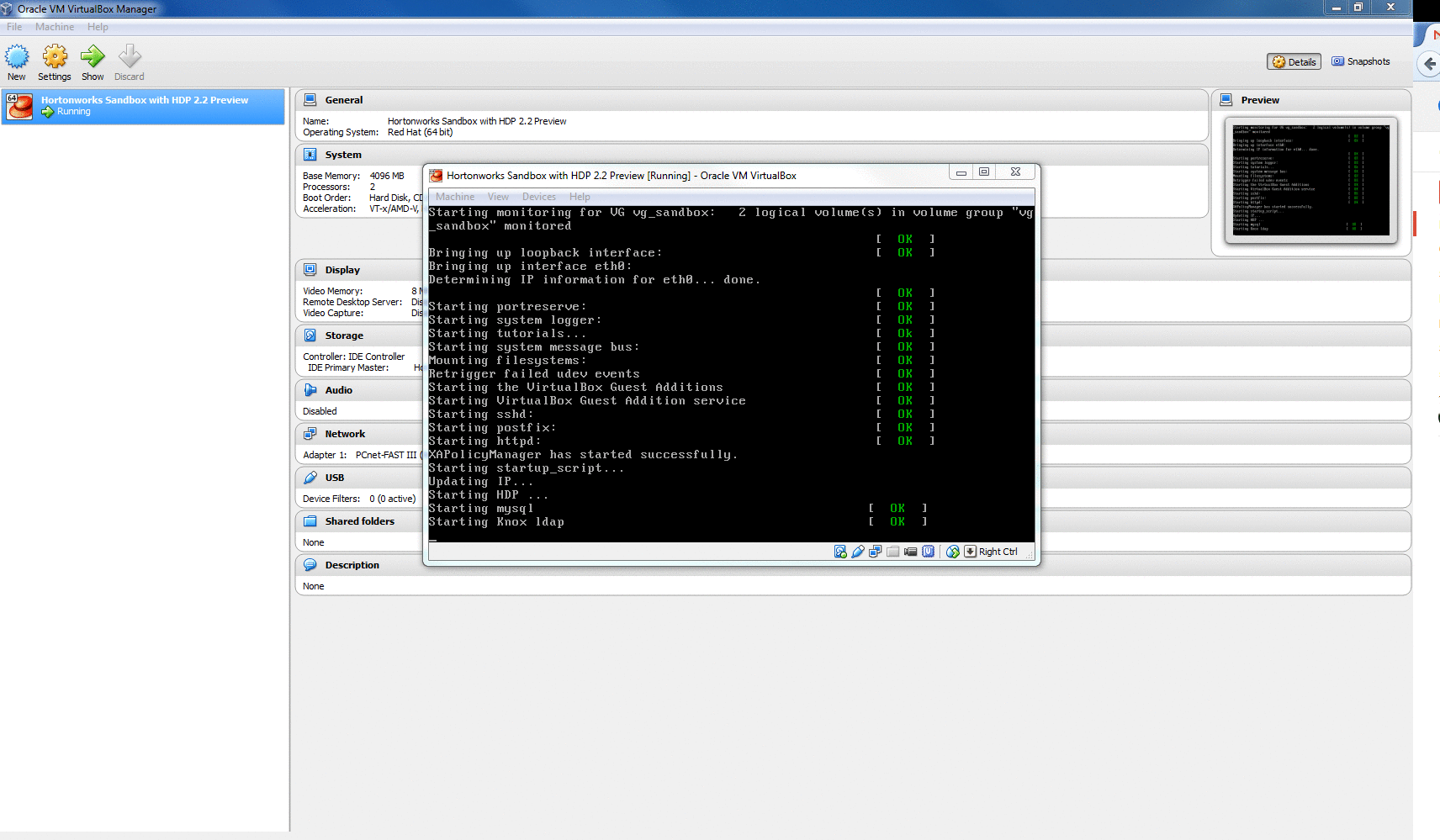
- Step 2: Sandbox is ready. Very important to note the IP address because we will use it later for ODBC connection with Excel.
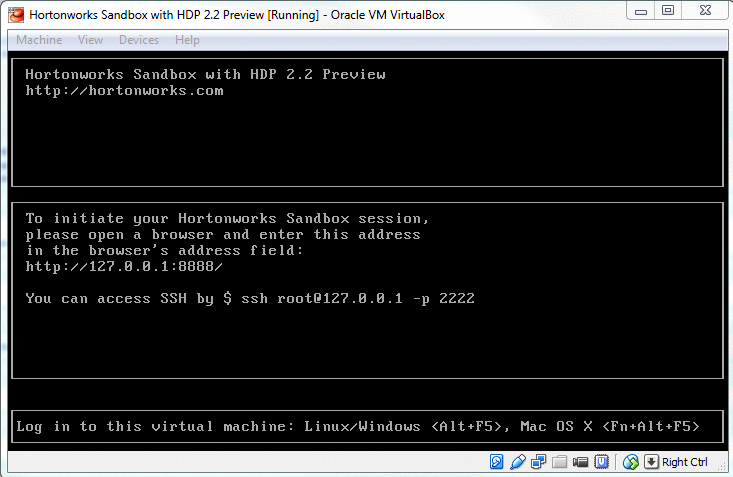
There are many blogs like this if you want to custom configure VirtualBox network settings and add a new host-only network other than the default NAT settings provided. Be careful about setting your sandbox ip address and the hive server ip address the same. Though not an issue (I suppose), it is recommended not to have them both the same. In such a custom case, the ifconfig on your sandbox will show both ethernet and loop back.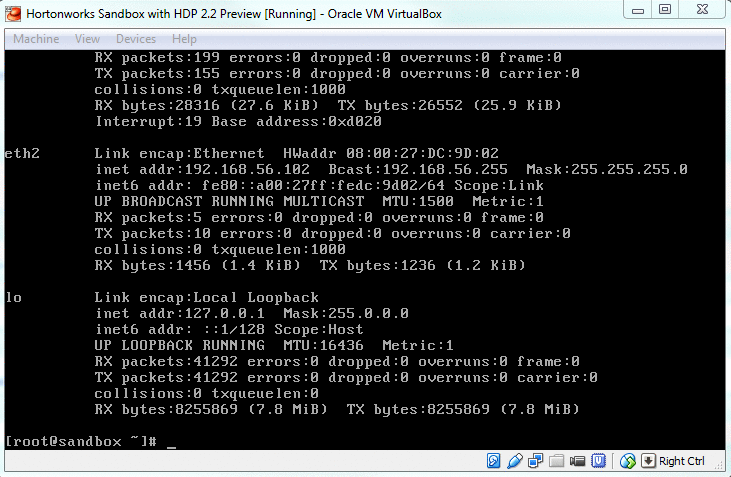
- Step 2a [skip if you have latest version of sandbox]: Now we need to make sure we have Flume which will send metadata of the log being monitored (eventlog-demo in this case) to Hive server. Notice that Flume is already configured in the latest version of sandbox and hence you can skip this part from the tutorial.
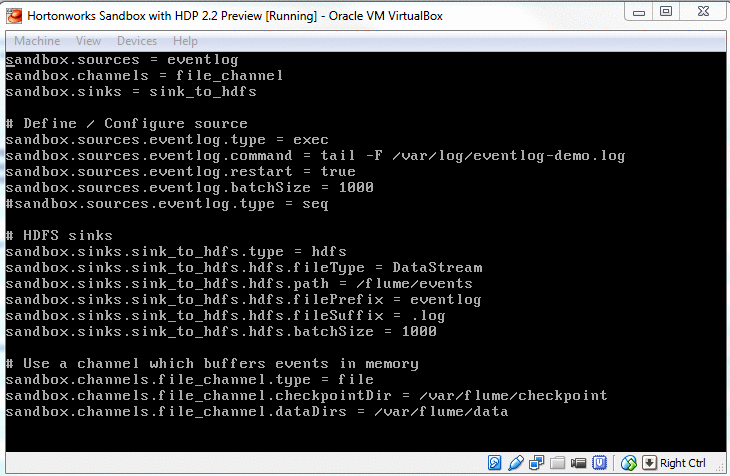
- Step 2b [skip if you have latest version of sandbox]: Log4j is the event logger used by Hadoop. We need to make sure its properties are intact. In our case log4j properties should include flume and like said, latest version of sandbox already does that for you.
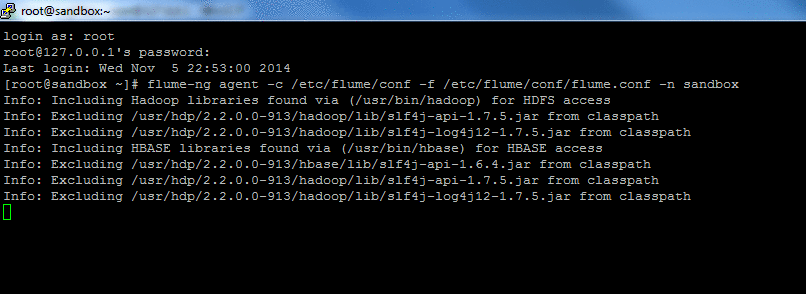
- Step 3: So simply go ahead and start Flume as mentioned in the tutorial. For this we log into sandbox from ssh and run the command given. WARNING: Command prompt wont return after you do this.
- Step 4 [Error in my case]: As per the tutorial, we now need to run the python script to generate log records into eventlog-demo file. It just would NOT work for me. Felt like my sandbox got stuck! So I just created the log by myself on a linux machine (my laptop) and copied the file into my sandbox using WinSCP. The copying event will still trigger Flume to do its work.
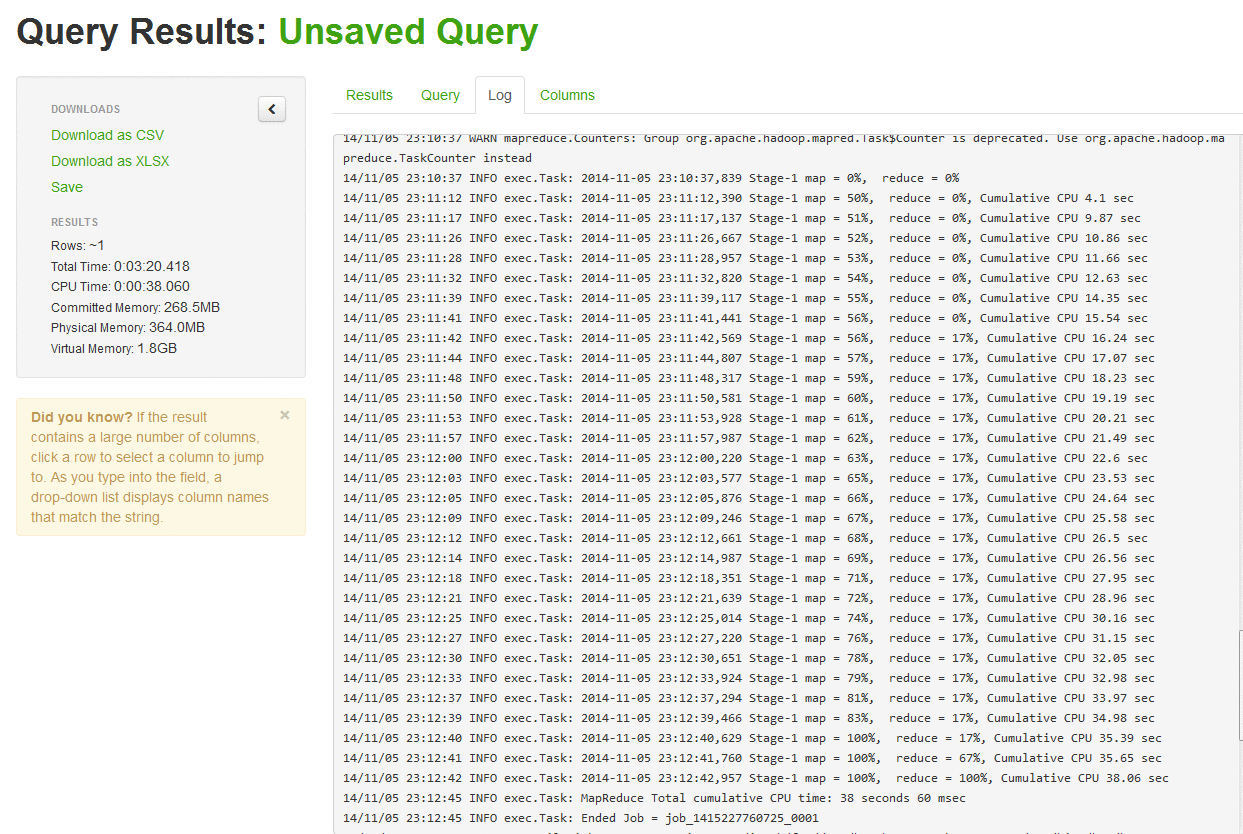
To confirm, I checked the flume log.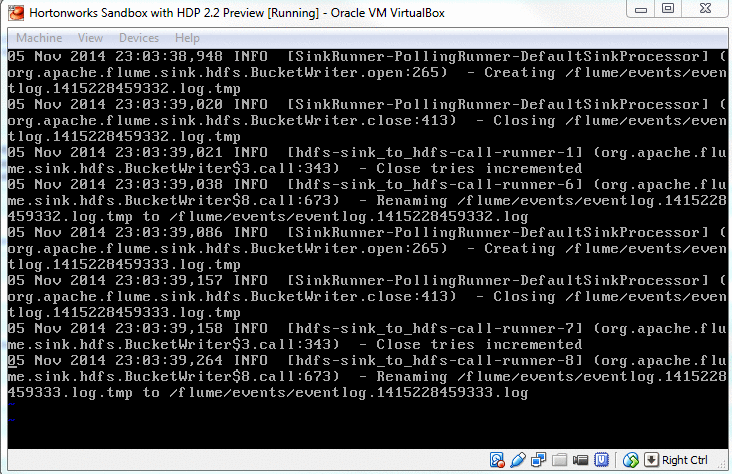
Only issue is, I had to wait for few seconds to allow Flume to finish its work so that I can manually (ctrl+C) stop it.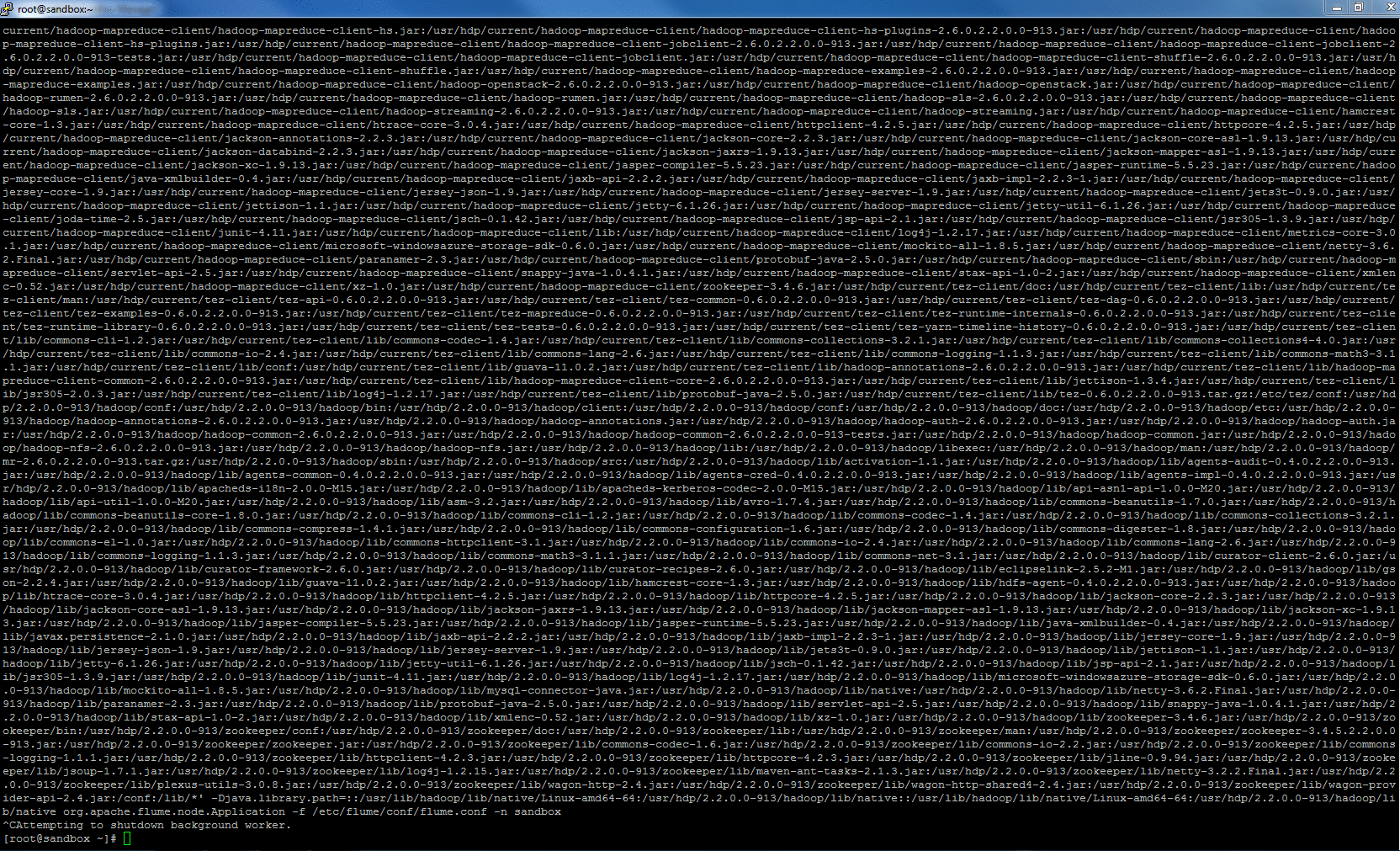
- Step 5: Now we create a table in Hcatalog to give the data in hive server some format.

The table can be accessed and queried from the browser. Since the default limit is only 250 rows, we can start some map reduce jobs to actually look at the entire data.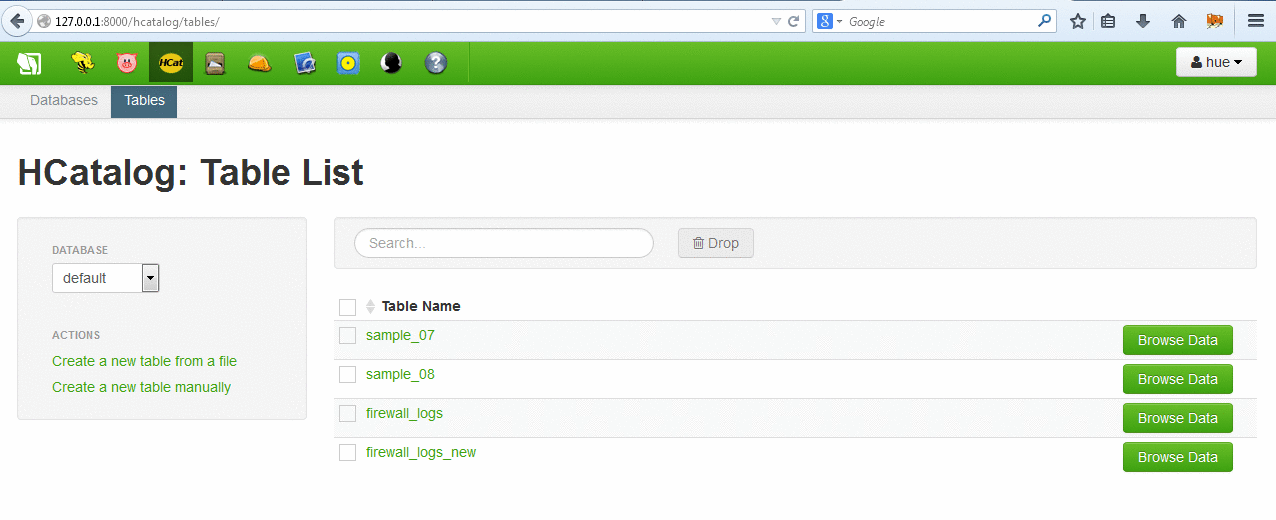
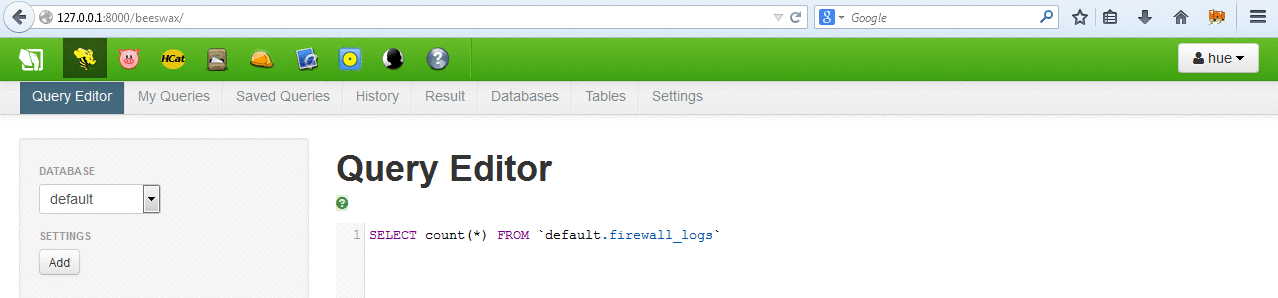
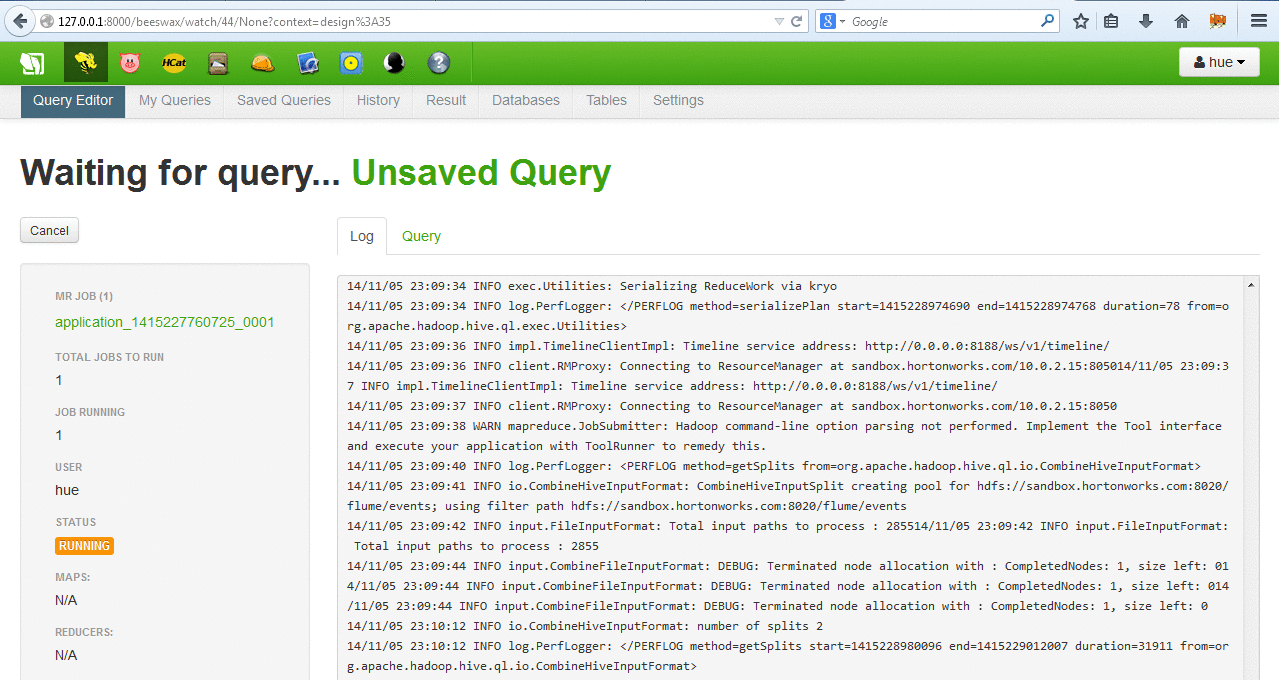
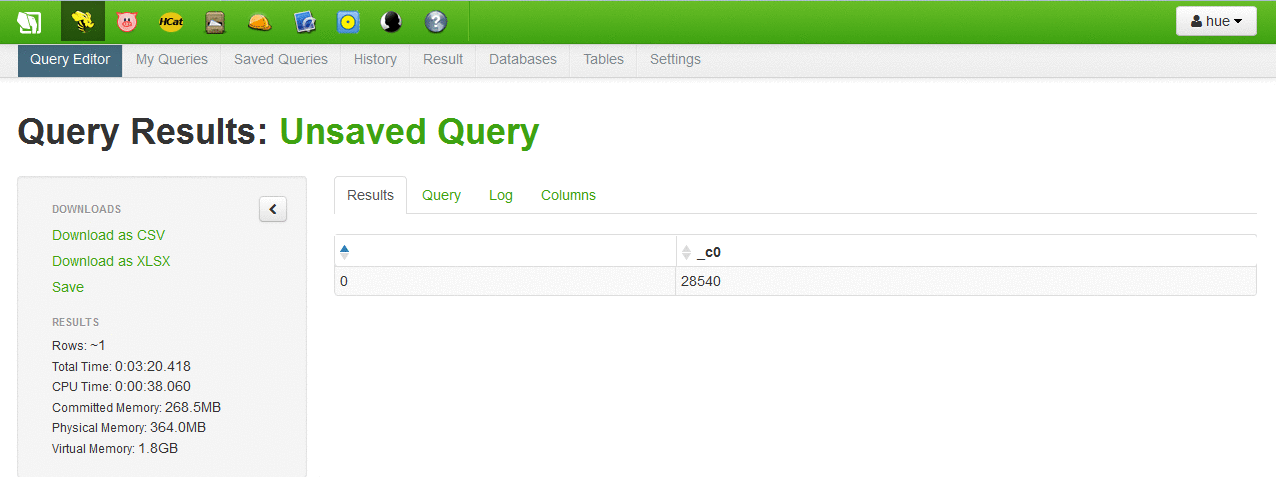
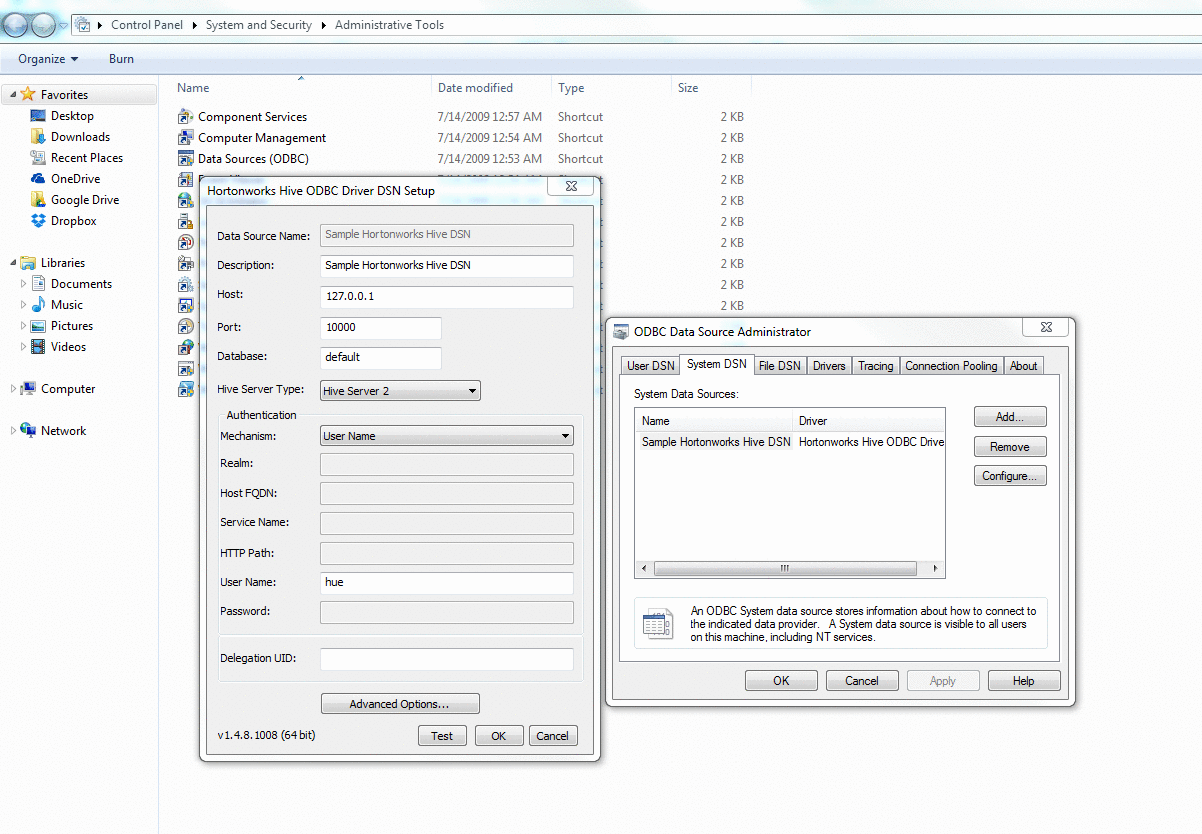
- Step 6 [Error in my case]: Once flume puts the table/data in the hive server, the tutorial asks to use Microsoft Excel 2013 (power view) to view the log data with fancy interface. For this we need to download and install ODBC driver from hortonworks (available here) and attach our log data to Excel using the same. This did not work for me! I researched quite a bit online and none of the tricks worked for me. I used localhost/127.0.0.1/host-only network IP to connect the ODBC driver but none worked. Connection failed or timedout every single time.
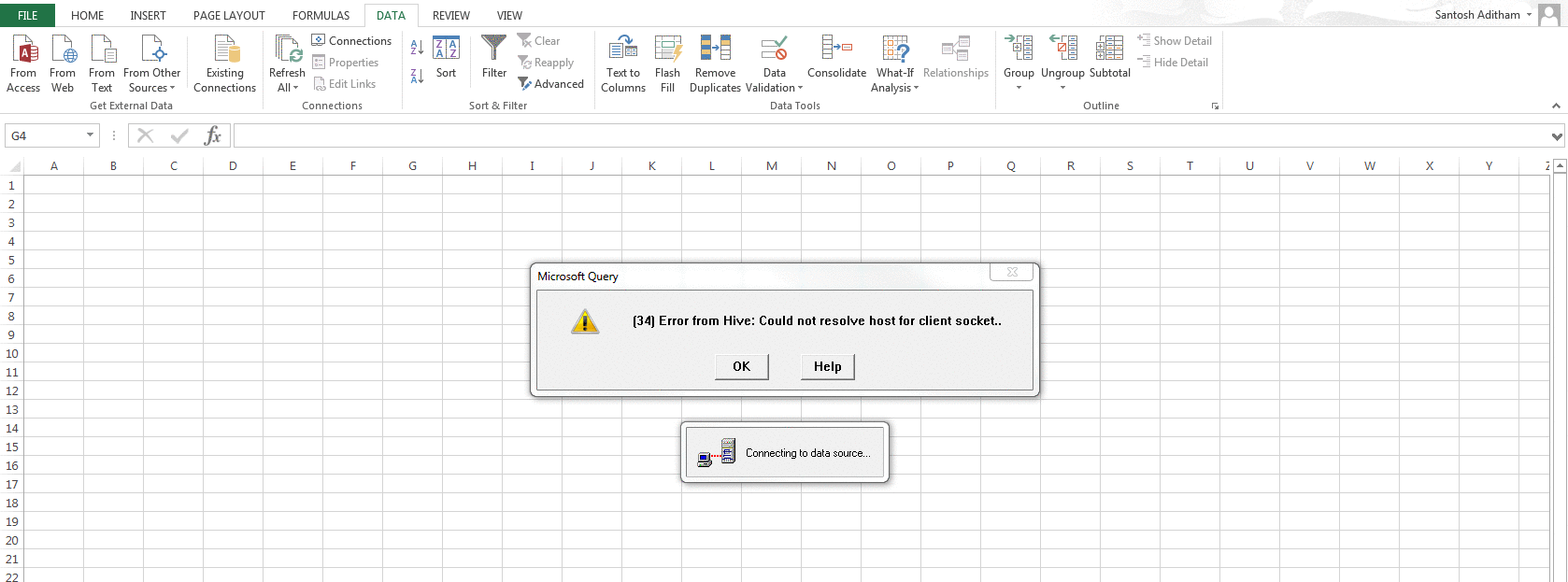
- Step 7: So, I just downloaded the data in my table into xlsx format and followed the steps mentioned in the tutorial to get the below output.
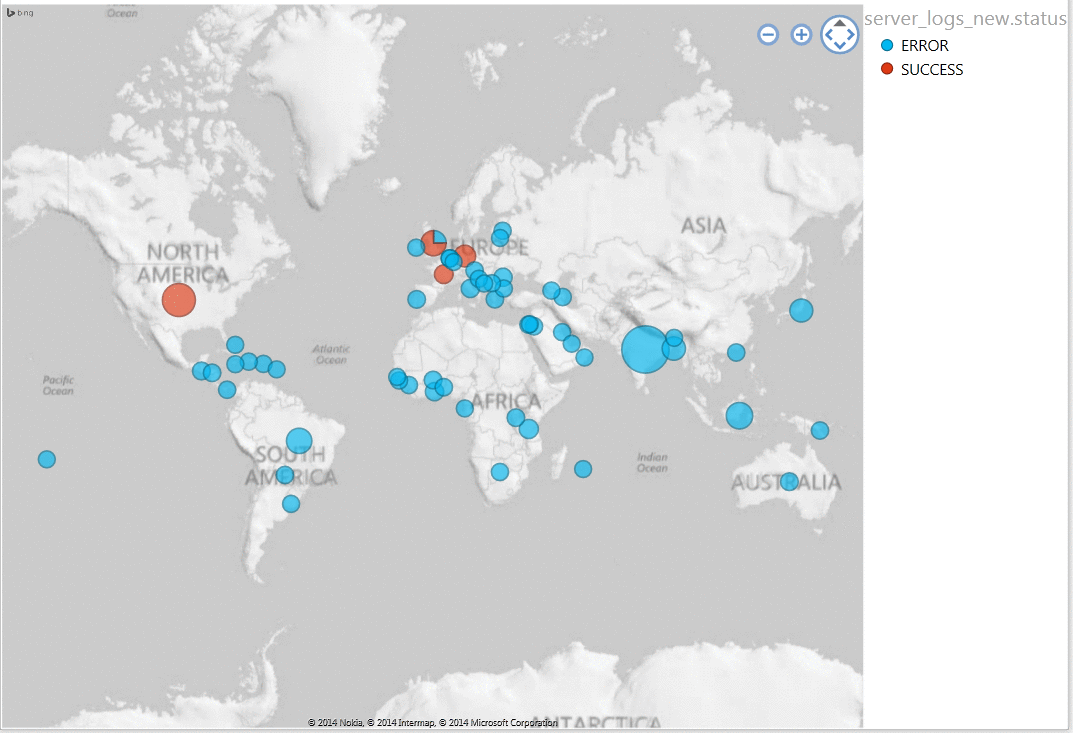
Learning
- Need lot of RAM before doing any administration stuff on hadoop
- Virtual Box is an ocean in itself
- Hortonworks tutorial is great but has holes to fill-in. One solution doesn't fit all
- Security in hadoop is vulnerable. So, there is scope for my new project!